
Study Anything 🧐
[PySpark] 쥬피터 노트북으로 PySpark 사용하기 본문
저번 포스트에서는 windows10 에 스파크를 설치해보았다.
다만 cmd 창에서 모든 작업을 진행하기에는 불편함이 있어서 (작업 명령어 등 내용 저장에 불편)
앞으로는 쥬피터 노트북으로 작업하기 위해 작업환경을 세팅하고 테스트로 데이터를 불러와보았다.
쥬피터 노트북과 아나콘다는 이미 설치되어 있다고 가정한다.
데이터를 저장하고 관리하기 위해 하둡을 함께 사용한다. (하둡 설치 방법은 이전 포스트 참고)
즉, 이번 포스트에서 다루는 내용은 스파크와 하둡을 연결하는 내용이라고 볼 수 있겠다.
(1) 하둡 실행
cmd 창을 열어 하둡 설치파일이 있는 디렉토리로 이동하고 다음 명령어들을 차례로 실행한다.
이 때 'hdfs namenode -format' 명령은 할 때마다 실행하지 않고 맨 처음에만 실행해도 되는 것 같다.
만약 해당 명령어를 입력하고 'Re-format filesystem in Storage Directory root= C:\(생략)\namenode; location= null ? (Y or N)' 라는 질문이 뜨면 n 을 입력하면 된다. (위치가 null이냐는 의미)
...> cd C:/Hadoop/Hadoop-3.2.2
C:\Hadoop\Hadoop-3.2.2> cd etc/hadoop
C:\Hadoop\Hadoop-3.2.2\etc\hadoop> hadoop-env
C:\Hadoop\Hadoop-3.2.2\etc\hadoop> hdfs namenode -format
이 다음으로 네임노드, 데이터노드, yarn 데몬들을 실행해 하둡 환경을 구동한다.
이들을 실행하고 확인하는 자세한 내용은 이전 포스트 후반부에 다뤄놓았다.
C:\Hadoop\Hadoop-3.2.2\etc\hadoop> cd ../../sbin
C:\Hadoop\Hadoop-3.2.2\sbin> start-dfs
C:\Hadoop\Hadoop-3.2.2\sbin> start-yarn
하둡이 정상적으로 실행되었다면 다음 명령어들을 입력해 하둡 저장소에 디렉토리와 파일을 추가한다.
mkdir 은 디렉토리를 생성하는 명령어, put 은 디렉토리에 파일을 업로드하는 명령어이다.
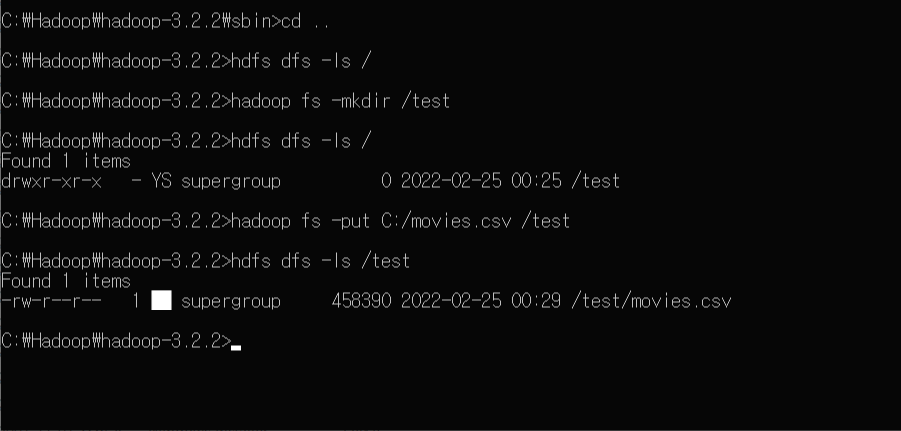
(2) 환경 변수 입력
쥬피터 노트북에서 파이스파크(PySpark)를 사용하기 위해서는 환경 변수를 설정해야 한다.
('설정 > 시스템 > 정보 > 고급 시스템 설정 > 고급 > 환경변수'를 통하거나 윈도우 검색창에 '환경변수'를 입력한 후 '시스템 환경 변수 편집'을 클릭해 환경변수 창을 띄운다.)
환경 변수 중 시스템 변수 부분에서 새로 만들기를 클릭한 후 두 변수를 추가한다.
| 변수 이름 | PYSPARK_DRIVER_PYTHON | PYSPARK_DRIVER_PYTHON_OPTS |
| 변수 값 | jupyter | notebook |
사용자 변수나 시스템 변수 중 Path 변수 내용에 아나콘다가 등록되어 있는지도 확인한다.

(3) 쥬피터 노트북 실행
쥬피터 노트북을 실행하고 새로운 파이썬 노트북 파일을 만든 뒤 다음의 단계를 따른다.
[1] findspark 라이브러리 설치
pip install findspark
[2] findspark 임포트 후 초기화
import findspark as fs
fs.init()
[3] 스파크 세션 생성
# spark 생성
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
[4] 하둡 저장소에서 스파크를 이용해 데이터 불러오기
localhost 뒤의 포트 번호는 각자의 하둡 환경에 맞는 포트 번호를 넣으면 된다.
data = spark.read.csv("hdfs://localhost:9000/test/movies.csv", header="true", inferSchema="true")
[5] 데이터 확인
명령을 실행했을 때 다음처럼 데이터 파일의 내용이 나오면 성공이다!
data.show()
이제 하둡과 스파크를 이용해 데이터를 다룰 모든 준비가 끝났다.
다음 단계로는 분석할 데이터를 모으고 스파크를 사용해 처리해보도록 하겠다.
'스터디 > Data Analytics' 카테고리의 다른 글
| 데이터 분석 프레임워크 - AARRR (해적지표) (0) | 2022.03.16 |
|---|---|
| [Hadoop] 맵리듀스 - 분산 데이터 처리 프레임워크 (0) | 2022.02.26 |
| [Hadoop] YARN - 리소스 관리자와 스케줄러 (0) | 2022.02.24 |
| [Hadoop] 하둡 설치하고 확인해보기 (0) | 2022.02.23 |
| [Spark] 스파크 설치하고 csv 파일 불러오기 (0) | 2022.02.15 |
