스파크를 사용할 때 저장소로 하둡을 사용하기 위해 하둡을 설치해보겠다.
하둡 설치는 다음 과정을 따른다.
(1) 하둡, 자바 다운
https://hadoop.apache.org/releases.html
위 링크에서 받으려는 하둡 버전을 확인하고 binary 를 선택해 압축파일을 다운받는다.
압축파일은 ~.tar.gz 확장자 이름을 가지고 있고 나는 3.2.2 버전을 받았다.
(스파크에 포함된 하둡 버전이 3.2 버전이다.)
자바(jdk)도 다운받아야 하지만 자바는 이미 있기 때문에 해당 과정은 생략한다. (나의 자바 버전 13)
(2) 환경변수 설정
스파크 설치 때와 마찬가지로 환경변수를 설정한다. (이전 게시글에서 자세히 다뤘으므로 여기서는 패스한다.)
다만 이전에 설정했던 HADOOP_HOME 을 편집해서 압축해제한 폴더로 설정한다.
(나의 경우 : (기존) C:\Hadoop → (변경) C:\Hadoop\hadoop-3.2.2)
스파크 설치 때 다운받았던 C:\Hadoop\bin 폴더의 winutils.exe 파일도 해당하는 같은 경로에 추가한다.
(나의 경우 : C:\Hadoop\hadoop-3.2.2\bin 폴더로 이동)
(3) 하둡 버전 확인
하둡이 제대로 설치되었는지 확인하기 위해 하둡 버전을 확인해보았다.

내 환경의 jdk 버전이 13이기 때문에 자바 버전이 13인 것이 확인되고 있다.
혹시 이 때 '지정된 경로를 찾을 수 없습니다. Error: JAVA_HOME is incorrectly set.' 오류가 발생한다면
이것은 환경 변수의 JAVA_HOME 에 띄어쓰기가 포함되었기 때문으로
C:\Program Files\ 라면 C:\Progra~1\ 으로, C:\Program Files(x86)\ 이라면 C:\Progra~2\ 으로 변경한다.
(4) 파일 수정
C:\Hadoop\hadoop-3.2.2\etc\hadoop 폴더로 이동해 파일들을 수정한다.
수정할 파일은 모두 5개이며, 중간에 C:\Hadoop\hadoop-3.2.2 안에 data\datanode 폴더와 data\namenode 폴더를 만든다. 이 과정은 아래 링크를 참고했다.
https://codedragon.tistory.com/9582
(4) 설치 확인
위 과정을 모두 마친 후 cmd 창에서 다음 명령어를 입력해 폴더로 이동한다.
...> cd C:\Hadoop\hadoop-3.2.2\etc\hadoop차례대로 명령어들을 입력한다.
...\etc\hadooop> hadoop-env
...\etc\hadooop> hadoop namenode -format각종 INFO 가 확인되며 HDFS 를 기반으로 한 경로가 보인다.
이어서 폴더를 이동한 후 계속 진행한다.
start-dfs 명령어를 입력하면 namenode 와 datanode 와 관련된 창 2개가 띄워진다.
방화벽 관련 창이 띄워진다면 액세스를 허용한다.
새로 띄워진 창에 더 이상 새로운 내용이 업데이트되지 않으면 원래의 cmd 창에서 계속 진행한다.
start-yarn 명령어를 입력하면 yarn 데몬이 실행된다. 마찬가지로 2개의 창이 구동된다.
...\etc\hadoop> cd ../../sbin
...\sbin> start-dfs
...\sbin> start-yarn
마지막으로 다음 페이지들이 잘 구동되는지 확인한다.
- 네임노드 정보 (NameNode Information) : http://localhost:9870/
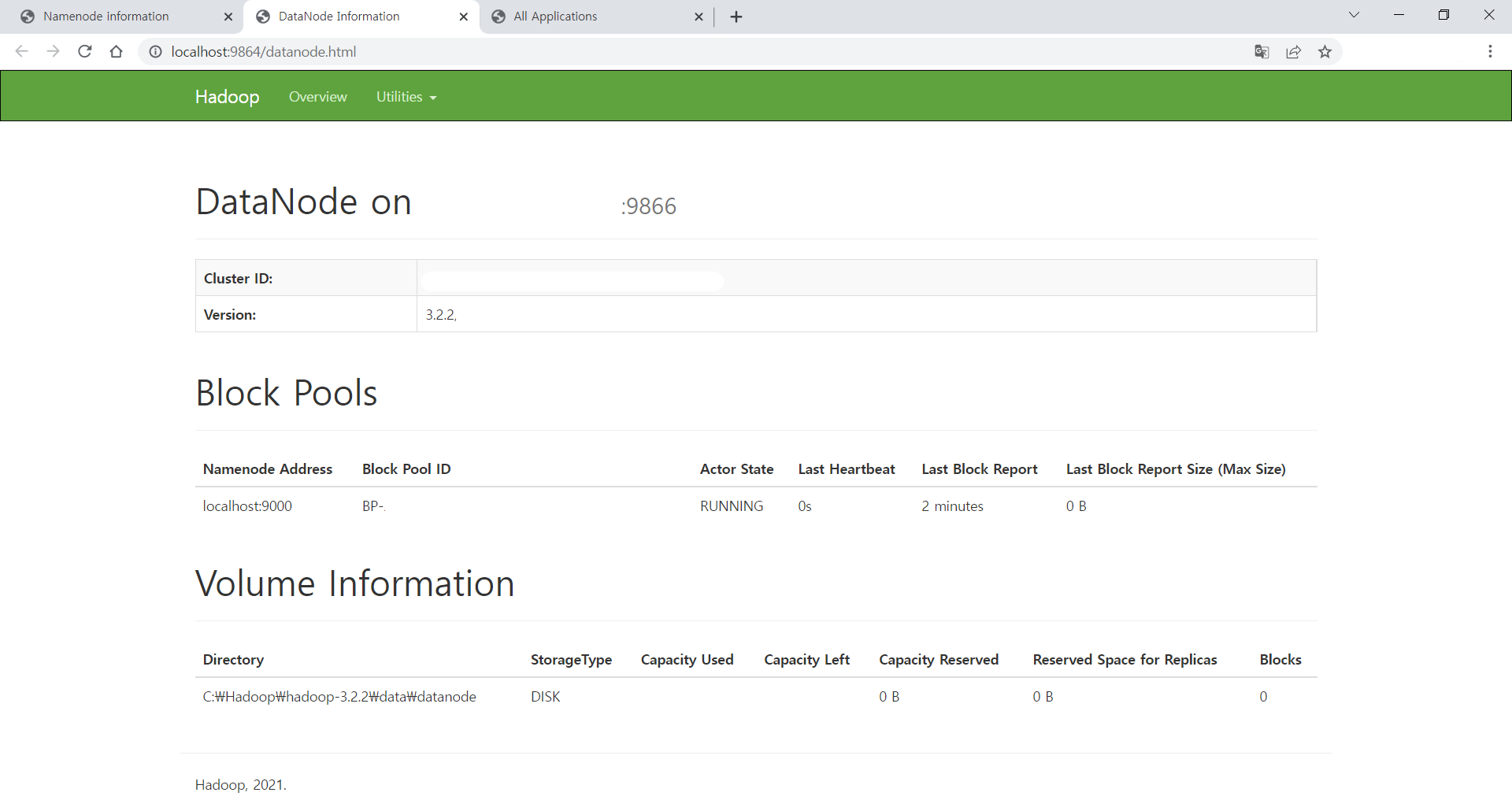
- 데이터노드 정보 (DataNode Information) : http://localhost:9864/
- YARN 정보 (YARN Information) : http://localhost:8088/
차례대로 다음과 같은 웹페이지가 띄워진다.
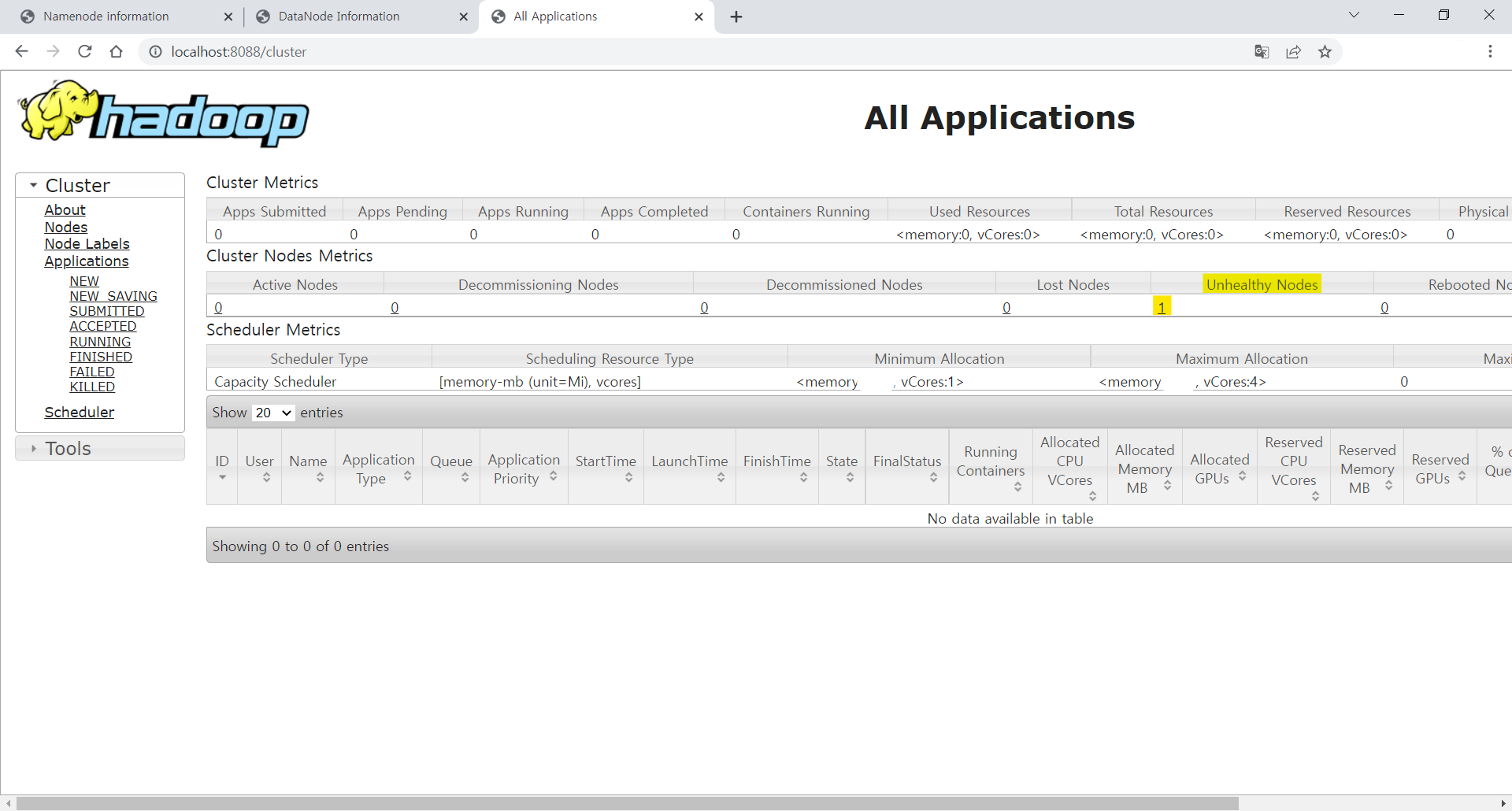
하지만 나의 경우 YARN 데몬을 실행했을 때 resourcemanager 에서
'ERROR capacity.CapacityScheduler: Attempting to remove non-existent node ~' 의 오류가 발생했다.

위의 캡쳐화면에서 보다시피 YARN 정보창은 잘 뜨기는 했지만 자세히 보면 Cluster Nodes의 Unhealty Nodes 부분에 1이 추가되어 있는 것을 볼 수 있다.
이것은 내 PC의 저장용량이 90% 이상 차있을 때 발생하는 현상이었다..
PC의 용량을 정리하고 어느 정도의 용량을 확보한 뒤에 위 명령들을 실행했더니 오류도 생기지 않았고 YARN 정보창의 클러스터 노드 Active Nodes 부분에 1이 추가된 것을 확인할 수 있었다.
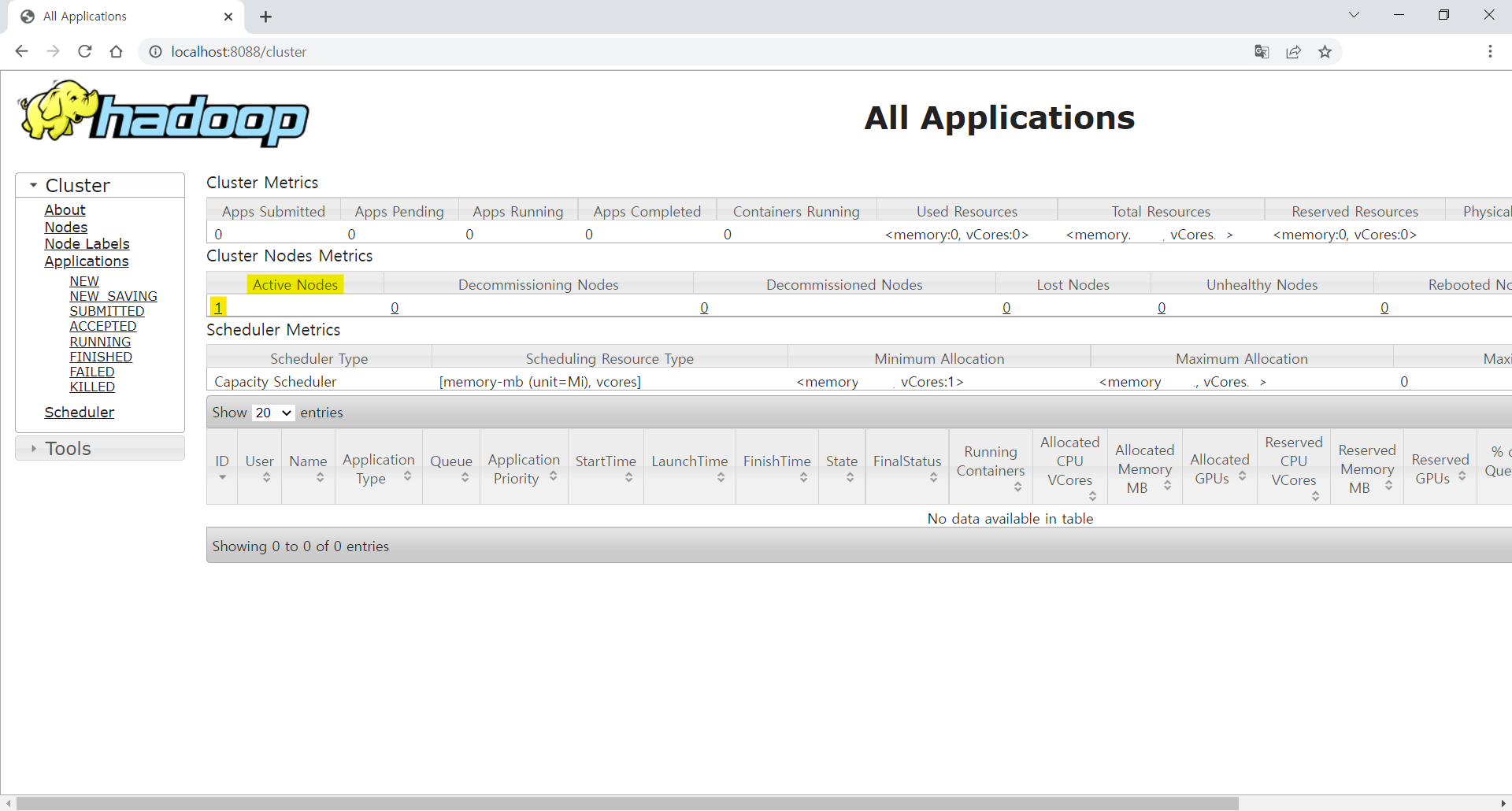
이처럼 혹시 모를 오류들에 대비해 평소 PC의 용량을 잘 정리하도록 하자... (실제로 이 오류 해결 때문에 며칠을 날림..)
'스터디 > Data Analytics' 카테고리의 다른 글
| [PySpark] Jupyter Notebook에서 PySpark 사용하기 (0) | 2022.02.25 |
|---|---|
| [Hadoop] YARN - 리소스 관리자와 스케줄러 (0) | 2022.02.24 |
| [Spark] 스파크 설치하고 csv 파일 불러오기 (0) | 2022.02.15 |
| [Hadoop] 하둡과 분산 파일 시스템 (0) | 2022.02.14 |
| [Pandas] 판다스와 시리즈 기본 (0) | 2022.02.06 |