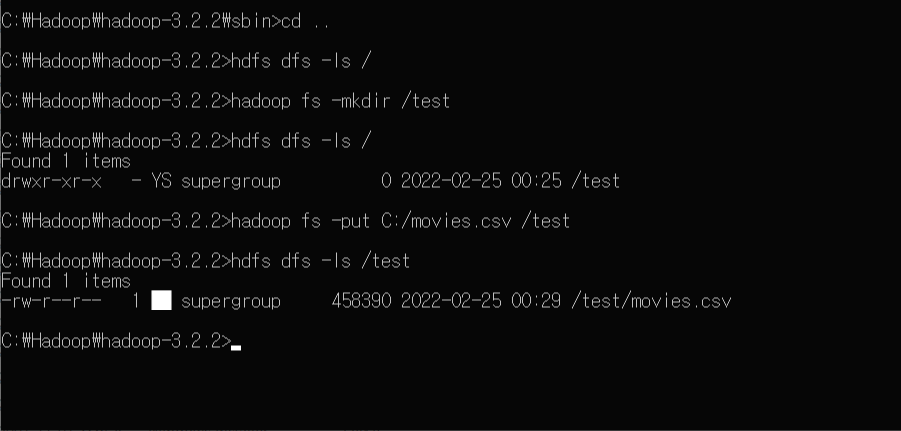
지난 포스트에서는 크롤링으로 수집한 데이터를 통해 선수의 공격과 수비 지표로 쓸 수 있는 공격 성공률, 리시브 효율, 세트당 서브/세트/블로킹/디그 수 등을 구했다. 하지만 공격 지표 중에는 공격 성공률 뿐 아니라 공격이 얼만큼의 효과를 냈는지 보는 '공격 효율' 또한 중요하다. 공격 효율은 (공격 성공-공격 범실)/공격 시도 로 구한다. 그러나 크롤링 당시 전체 범실 개수만 저장하고 공격에서의 범실은 저장하지 않아서 추가로 공격 범실 데이터가 필요했다. ( 데이터 새로 얻는 과정은 생략 ) 새롭게 얻은 데이터이다. 이제 기존에 작성했던 코드 중 공격 효율(at_rate)을 계산하는 부분을 추가한다. 공격 성공률, 공격 효율, 리시브 효율은 모두 백분율이므로 이전에 전처리 할 때 놓쳤던 백분율 변환 부분..