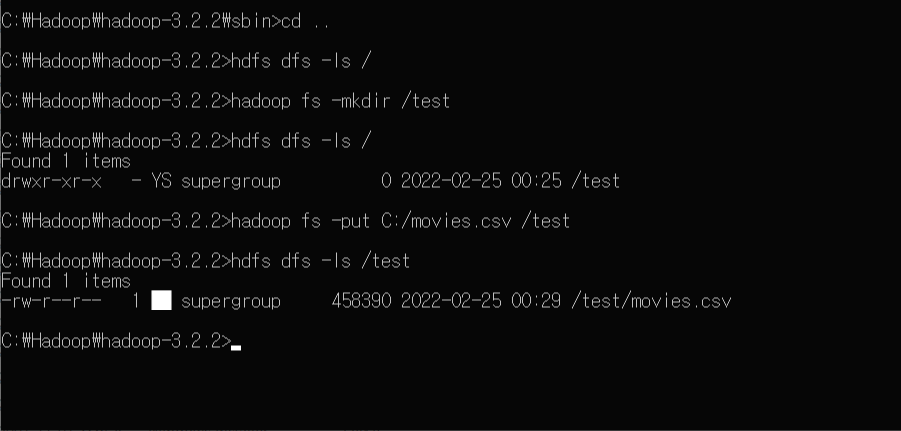
AARRR 기법은 그로스 해킹(Growth Hacking) 의 분석 기법이다. 그로스 해킹은 기업의 성장을 최우선으로 하며, 사용자의 데이터를 분석해 서비스를 개선하는 데에 활용하기 때문에 이런 이름이 붙게 되었다. 다섯 단어의 앞 글자를 땄으며 각각 Acquisition(획득), Activation(활동), Retention(재방문), Referral(공유), Revenue(수익) 이다. 사용자가 서비스를 활용하면서 수집되는 여러 데이터 중 위 다섯가지의 지표를 핵심으로 서비스의 성장에 활용한다. 다섯 개의 지표를 순차적으로 분석하는 것이 아니라 함께 분석해야 한다. (1) Acquisition 획득 단계에서는 소비자가 서비스를 어떻게 알게 되었는지, 어떤 경로로 유입되었는지 등을 분석한다. DAU, ..