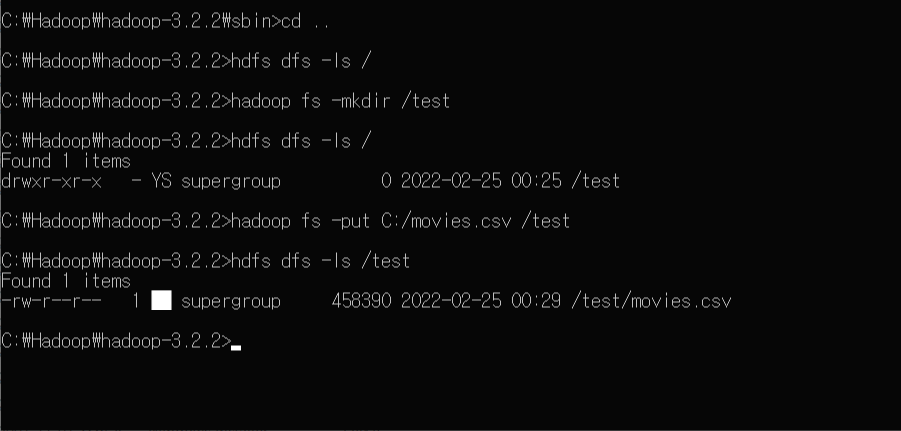
LLM에 대해 공부하다 보면 LangChain이라는 단어를 자주 접하게 된다. LangChain이 과연 무엇일까? 이번 포스팅에서 한 번 다뤄보려고 한다. 0. LLM우선 LLM은 Large Language Model의 약자로, 대규모 언어 모델이라는 뜻이다. 널리 사용되는 OpenAI의 GPT(ChatGPT), Meta의 LLaMA, Google의 Gemini 등이 있다. 텍스트로 지시를 하면 해당하는 내용을 텍스트로 생성하여 반환한다. 이렇게 적절한 결과를 반환하기 위해서 모델은 상당한 양의 데이터를 보유해야 한다. 이것이 모델에 "대규모(Large)"라는 단어가 붙는 이유이다. 1. LangChain?LLM에 대한 내용은 이쯤에서 넘어가고, 그렇다면 LangChain은 도대체 뭘까?..