지난 포스트에서는 크롤링으로 수집한 데이터를 통해 선수의 공격과 수비 지표로 쓸 수 있는
공격 성공률, 리시브 효율, 세트당 서브/세트/블로킹/디그 수 등을 구했다.
하지만 공격 지표 중에는 공격 성공률 뿐 아니라 공격이 얼만큼의 효과를 냈는지 보는 '공격 효율' 또한 중요하다.
공격 효율은 (공격 성공-공격 범실)/공격 시도 로 구한다.
그러나 크롤링 당시 전체 범실 개수만 저장하고 공격에서의 범실은 저장하지 않아서 추가로 공격 범실 데이터가 필요했다.
( 데이터 새로 얻는 과정은 생략 )
새롭게 얻은 데이터이다.

이제 기존에 작성했던 코드 중 공격 효율(at_rate)을 계산하는 부분을 추가한다.
공격 성공률, 공격 효율, 리시브 효율은 모두 백분율이므로 이전에 전처리 할 때 놓쳤던 백분율 변환 부분도 추가했다.
# 경기 지표 계산한 테이블 만들기
player_rate = spark.sql("""
select name,team,pos,score,error,setcount,
round(at_succ/at_try*100,2) as at_srate,round((at_succ-at_err)/at_try*100,2) as at_rate,
...
round((rs_corr-rs_fail)/rs_try*100,2) as rs_rate,...
from player
""")
player_rate.show()
하지만 아래 데이터를 보면 중간중간 결측값들이 있는 것을 볼 수 있다. 이유는 선수들의 포지션 특성 때문이다.
데이터에서 보이는 리베로 포지션은 수비 전문 포지션으로,
공격에는 참여하지 않으며 공격으로 판단되는 행위를 하면 이는 범실로 처리된다.
따라서 공격 성공률, 공격 효율이 null 인 경우는 공격 시도가 0이기 때문이고
공격 성공률이 0, 공격 효율이 -100 인 경우는 공격을 시도했다고 판단됐으나 범실로 기록되었기 때문이다.
마찬가지로 리시브 효율이 null 인 경우 또한 리시브 시도가 없기 때문이다.
# 참고
공격 성공률(%) : 성공/시도
공격 효율(%) : (성공-범실)/시도
리시브 효율(%) : (정확-실패)/시도
세트당 ~ (개) : 성공/참여한 세트수
이 결측값들을 처리하기 위해 아래와 같은 내용을 추가했다.
SQL 의 CASE 문 중 'CASE WHEN ~ THEN ~ ELSE ~ END AS 컬럼명' 표현을 사용해서
공격 성공률과 공격 효율, 리시브 효율에서 null 이거나 -100 인 값들을 0으로 변경했다.
# null 값, 의미없는 값 0으로 변경
player_rate2 = spark.sql("""
select ...,
case when at_srate is null then 0.0 else at_srate end as at_srate,
case when at_rate is null or at_rate = -100.0 then 0.0 else at_rate end as at_rate,
...,
case when rs_rate is null then 0.0 else rs_rate end as rs_rate,...
from player_rate
""")
player_rate2.show()데이터들이 잘 변경된 것을 볼 수 있다.
이렇게 해서 누락됐던 공격 효율과 결측값 처리를 모두 마쳤다!
(참고) 하둡에서 파일, 디렉토리 삭제하는 방법
추가적으로 이전에 잘못 만든 데이터들을 하둡에서 삭제하는 방법도 정리해두려고 한다.
먼저 > hadoop fs -rm /data/[파일명] 명령어로 어떤 데이터들이 있는지 확인했다.
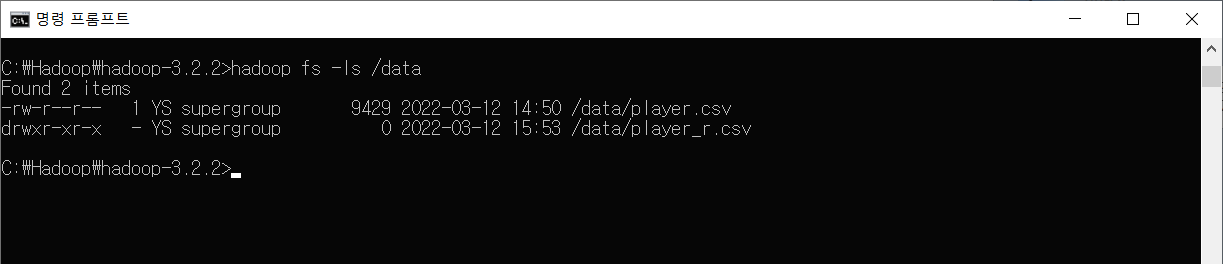
하지만 디렉토리라며 삭제가 되지 않고 > hadoop fs -ls /data 명령어로 확인해봤을 때 파일들이 그대로인 것을 볼 수 있다.
정확한 이유는 모르겠지만 스파크를 통해 저장한 데이터는 디렉토리처럼 인식되는 것 같다.
(그래서인지 크기도 0이라고 나옴)
그래서 디렉토리를 삭제하는 명령어로 삭제해주었다.
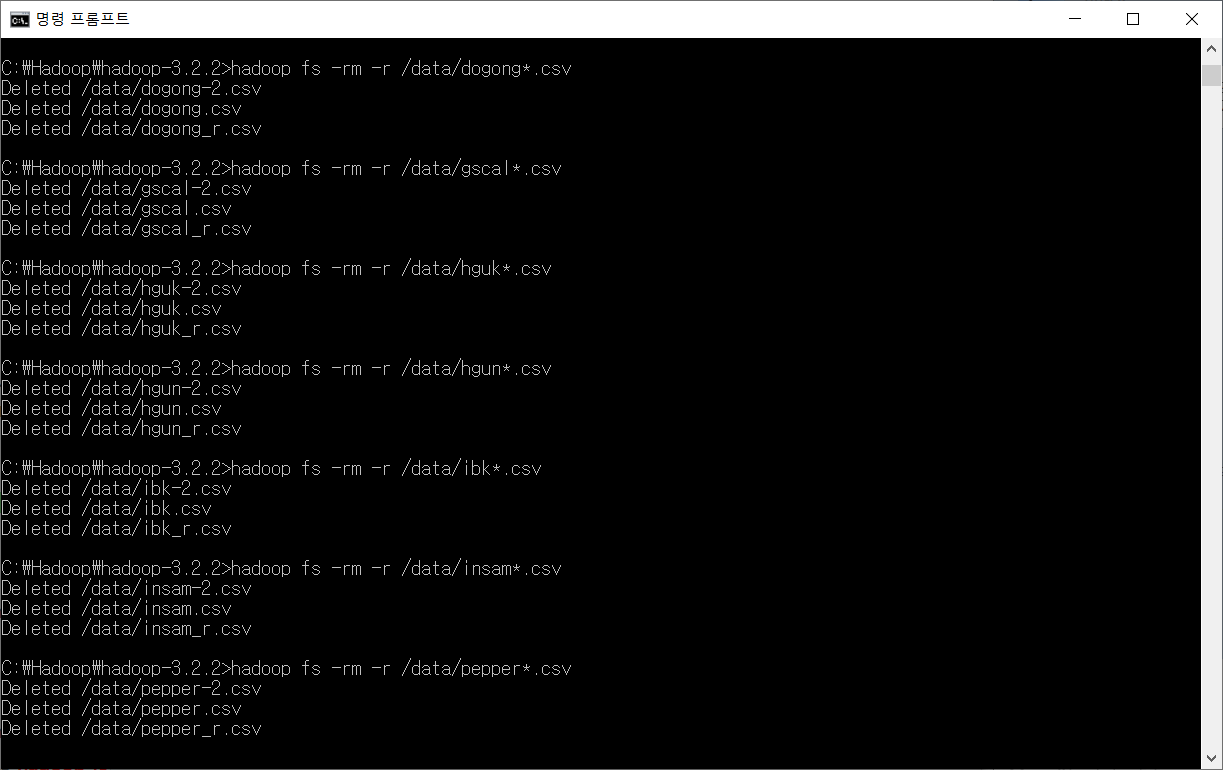
> hadoop fs -rm -r /data/[파일명] 명령어를 사용했는데, 리눅스와 마찬가지로 * 기호는 모든 문자를 의미하므로
만약 > hadoop fs -rm -r /data/dogong*.csv 라는 명령어를 입력하면
dogong.csv, dogong-2.csv, dogong_r.csv 들이 모두 삭제된다.
이 때 '.csv' 부분은 확장자명이라서 그런지 모르겠지만 * 뒤에 생략하면 안 된다.
삭제할 데이터들을 모두 삭제하고 확인해 본 모습이다.
'프로젝트 > [DA] 데이터 분석 : 배구' 카테고리의 다른 글
| 데이터 수집 (웹 크롤링) (3) - 경기 세부 데이터 (0) | 2022.03.27 |
|---|---|
| 데이터 수집 (웹 크롤링) (2) - 경기 데이터 (0) | 2022.03.26 |
| 데이터 전처리 - PySpark에서 SQL 사용하기 (0) | 2022.03.12 |
| 프로젝트 설명 & 데이터 수집 (웹 크롤링), 저장 - 선수 데이터 (0) | 2022.03.11 |